|
Introduzione
Cos'è il Text Mining? 
- Il Text Mining è una tecnica di Intelligenza Artificiale (AI) che utilizza l'elaborazione del linguaggio naturale (NLP) per trasformare il testo libero, non strutturato, di documenti/database quali pagine web, articoli di giornale, e-mail, agenzie di stampa, post/commenti sui social media ecc.
- In generale, il text mining può essere classificato in due tipi:
► Le domande dell'utente sono molto chiare e specifiche, ma non conoscono la risposta alle domande.
► L'utente conosce solo l'obiettivo generale ma non ha domande specifiche e precise.
Le sfide test mining
- Il testo del linguaggio naturale non è strutturato.
- La maggior parte dei metodi di data mining gestiscono dati strutturati o semi-strutturati=> l'analisi e la modellazione di testi non strutturati in linguaggio naturale è impegnativa.
- L'estrazione di dati di testo è di fatto una tecnologia integrata di elaborazione del linguaggio naturale, classificazione dei modelli e apprendimento automatico.
- Il sistema teorico di elaborazione del linguaggio naturale non è ancora stato pienamente stabilito.
- Le principali difficoltà incontrate nel text mining sono generate da:
► Il verificarsi di rumori o espressioni malformate,
► Espressioni ambigue nel testo,
► Difficoltà di raccolta e annotazione di campioni per alimentare i metodi di apprendimento automatico,
► Difficoltà di esprimere lo scopo e i requisiti del text mining.
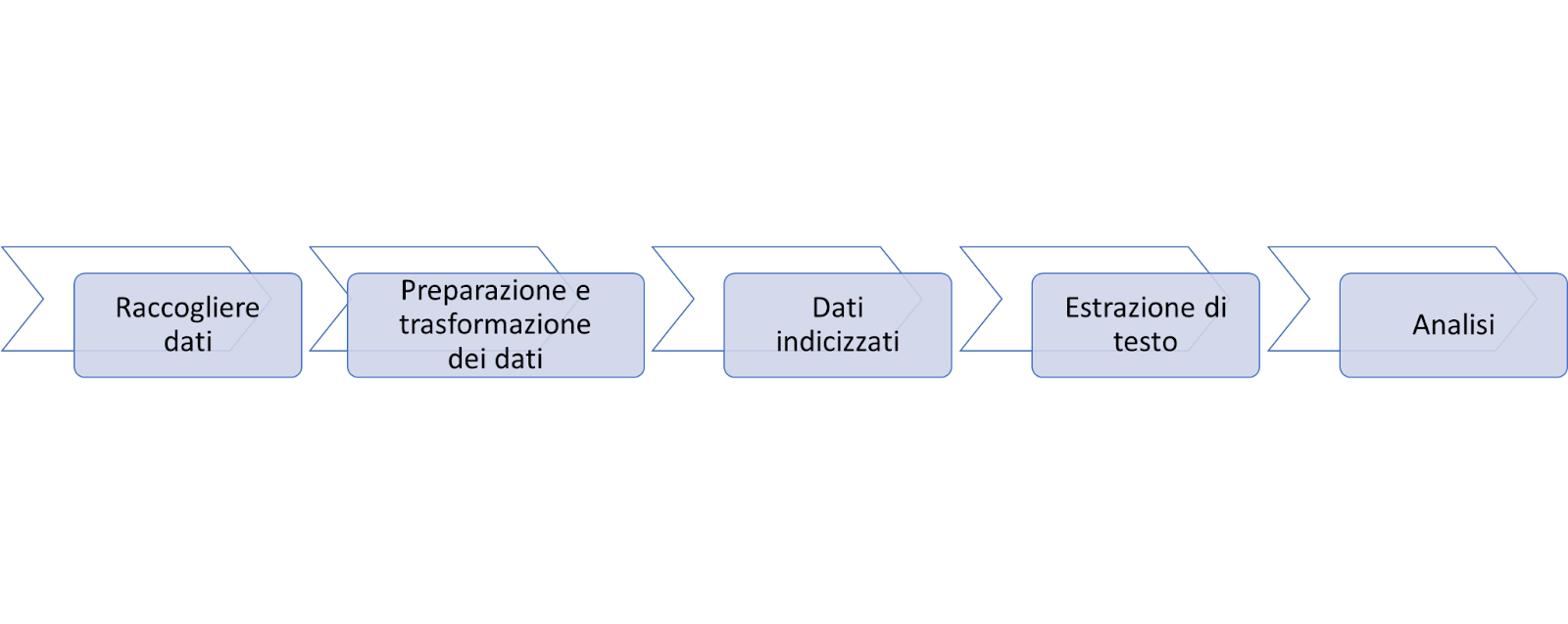
Flusso di elaborazione di text mining
Warning: file_get_contents(http://188.164.195.236/plesk-site-preview/datascience-project.eu/https/188.164.195.236/0BuTF13c2k_T5l4IOo_Mjm24-M2kyYe2V5fO9UUdH2CoLpO3XlDog2teXS2QNMUKuQ5KD1zQzLmNXfg79ypkvIkH7o9aN6Np01dCa3wxvaOIiQ7Uu_4amIk7Wuis8xvipkLiHHfHzM8Vfw_bb9Coq0k): failed to open stream: HTTP request failed! HTTP/1.1 404 Not Found
in /var/www/vhosts/internetwebsolutions.es/httpdocs/curso.php on line 670
- Il text mining esegue alcuni compiti generali per estrarre in modo efficace testi, documenti, libri, commenti:
Tecniche di text mining
Tecniche tipiche di text mining
Il text mining è un campo di ricerca che attraversa molteplici tecnologie e tecniche:
► I metodi di classificazione del testo dividono un determinato testo in tipi di testo predefiniti.
► Le tecniche di clustering di testo dividono un determinato testo in diverse categorie.
► Modelli tematici = modelli statistici utilizzati per estrarre gli argomenti e i concetti nascosti dietro le parole nel testo.
► Text sentiment analysis (text opinion mining) rivela le informazioni soggettive espresse dall'autore di un testo, cioè il punto di vista e l'atteggiamento dell'autore. Il testo è classificato in base agli atteggiamenti espressi nel testo o ai giudizi della sua polarità positiva o negativa.
► Il rilevamento di argomenti si riferisce all'estrazione e allo screening di argomenti di testo (argomenti caldi) affidabili per l'analisi dell'opinione pubblica, il social media computing e i servizi di informazione personalizzati.
► L'estrazione di informazioni si riferisce all'estrazione di informazioni fattuali come entità, attributi di entità, relazioni tra entità ed eventi da testo in linguaggio naturale non strutturato e semistrutturato che forma in output di dati strutturati.
► La sintesi automatica del testo genera automaticamente riassunti utilizzando metodi di elaborazione del linguaggio naturale.
Tecniche per la preparazione e la trasformazione dei dati
- La tokenizzazione refers to a process of segmenting a given text into lexical units.
- Rimuovere le parole di stop: Le parole stop si riferiscono principalmente a parole funzionali, tra cui parole ausiliarie, preposizioni, congiunzioni, parole modali e altre parole ad alta frequenza.
- Normalizzazione della forma di parola per migliorare l'efficienza dell'elaborazione del testo. La normalizzazione delle forme di parola comprende due concetti di base:
► Lemmatizzazione - il ripristino delle parole deformate in forme originali, per esprimere la semantica completa,
► Stemming - il processo di rimozione degli apposti per ottenere radici.
- L'annotazione dei dati rappresenta una fase essenziale dei metodi di apprendimento automatico supervisionati. Se la scala dei dati annotati è più grande, la qualità è più alta e, se la copertura è più ampia, le prestazioni del modello addestrato saranno migliori.
Basi della rappresentazione del testo
Basics of Text Representation
- Vector Space Model è il metodo di rappresentazione del testo più semplice.
- Concetti di base correlati:
► Il testo è una sequenza di caratteri con determinate granularità, come frasi, frasi, paragrafi o un intero documento.
► Il termine è la più piccola unità linguistica inseparabile che può indicare caratteri, parole, frasi, ecc.
► Il peso del termine è il peso assegnato a un termine secondo determinati principi, indicando l'importanza e la rilevanza di tale termine nel testo.
• Il modello di spazio vettoriale presuppone che un testo sia conforme ai seguenti due requisiti: (1) ogni termine ti è unico, (2) i termini non hanno ordine.
Rappresentazione del testo
• L'obiettivo del deep learning per la rappresentazione del testo è quello di apprendere vettori a bassa densità di testo a diverse granularità attraverso l'apprendimento automatico.
• Il modello bag-of-words è il metodo di rappresentazione del testo più popolare nelle attività di estrazione dei dati di testo come la classificazione del testo e l'analisi del sentiment.
• L'obiettivo della rappresentazione del testo è quello di costruire una buona rappresentazione adatta a specifici compiti di elaborazione del linguaggio naturale:
• L'obiettivo del deep learning per la rappresentazione del testo è quello di apprendere vettori a bassa densità di testo a diverse granularità attraverso l'apprendimento automatico.
► Per l'analisi del sentimento t chiedere, è necessario incarnare attributi più emotivi,
► Per le attività di rilevamento e tracciamento degli argomenti, devono essere incorporate ulteriori informazioni sulla descrizione degli eventi,
Classificazione del testo
Classificazione del testo
• Nella classificazione del testo, un documento deve essere rappresentato correttamente ed efficacemente per gli algoritmi di classificazione.
• La selezione di un metodo di rappresentazione del testo dipende dalla scelta dell'algoritmo di classificazione.
Algoritmi di apprendimento automatico di base per la classificazione del testo
• Algoritmi di classificazione del testo:
► Naive Bayes è un insieme di classificatori che lavora sui principi del teorema delle Bayes. Naïve Bayes modella la distribuzione congiunta p(x, y) dell'osservazione x e della sua classe y.
► L'entropia massima (ME) assegna la probabilità congiunta alle coppie di osservazione e di etichette (x, y) sulla base di un modello log-lineare:
 |
dove: è un vettore di pesi, f è una funzione che mappa le coppie (x, y) a un vettore di funzione di valore binario
|
► Support vector machines (SVM) è un algoritmo di apprendimento discriminativo supervisionato per la classificazione binaria.
► I metodi di ensemble combinano algoritmi di apprendimento multipli per ottenere prestazioni predittive migliori rispetto a uno qualsiasi degli algoritmi di apprendimento di base.
Introduzione nei modelli tematici
Introduzione nei modelli tematici
• I modelli tematici forniscono un metodo di rappresentazione concettuale che trasforma i vettori sparsi ad alta dimensione nel modello di spazio vettoriale tradizionalein vettori densi a bassa dimensione per alleviare la maledizione della dimensionalità.
• Modelli di argomento di base:
► L'analisi semantica latente (LSA) rappresenta un pezzo di testo da un insieme di concetti semantici impliciti piuttosto che i termini espliciti nel modello di spazio vettoriale. LSA riduce la dimensione della rappresentazione del testo selezionando k argomenti latenti invece di termini espliciti come
la base per la rappresentazione del testo utilizzando la seguente matrice di decomposizione:

► L'analisi semantica latente probabilistica (PLSA) estende la semantica latente il framework di algebra dell'analisi include la probabilità.
► L'allocazione di Dirichlet latente (LDA) introduce una distribuzione Dirichlet alla distribuzione di argomenti condizionali e alla distribuzione di termini condizionali.
BERT: Rappresentazioni bidirezionali Encoder da Transformer
• Bert è un modello di preformazione e messa a punto che utilizza l'encoder bidirezionale di Transformer.
• La rappresentazione di ogni token di input hj viene appresa sia nel contesto sinistro, x1, · · · , xj−1 che nel contesto destro xj 1, · · · , xn.
• I contesti bidirezionali sono cruciali in compiti come l'etichettatura sequenziale e la risposta alle domande.
• I contributi del BERT:
► Bert impiega un modello molto più profondo rispetto al GPT, e l'encoder bidirezionale è costituito da fino a 24 strati con 340 milioni di parametri di rete.
► Bert progetta due funzioni oggettive non supervisionate, tra cui il modello di linguaggio mascherato e la previsione delle frasi successive.
► Bert è pre-formato su set di dati di testo ancora più grandi.
Analisi dei sentimenti e Opinion Mining
• I compiti principali dell' analisi del sentimento e dell'estrazione di opinioni includono l'estrazione, la classificazione e l'inferenza di informazioni soggettive nei testi, come il sentimento, l'opinione, l'atteggiamento, l'emozione, la posizione.
• Le tecniche di analisi del sentimento sono naturalmente suddivise in due categorie:
► metodi basati su regole - eseguire l'analisi del sentimento a diverse granularità del testo sulla base dell'orientamento sentimentale delle parole fornite da un lessico sentimentale,
► metodi basati sull'apprendimento automatico si concentrano su un'efficace ingegneria delle funzionalità per la rappresentazione del testo e l'apprendimento automatico.
Caso di studio con Python
Librerie Python comuni per il Text Mining
Librerie Python comuni per il Text Mining
► NLTK (Natural Language Toolkit) – include potenti librerie per l'elaborazione del linguaggio naturale simbolico e statistico che possono lavorare su diverse tecniche di ML.
► SpaCy - libreria open-source per NLP in Python progettata per l'estrazione di informazioni o l'elaborazione del linguaggio naturale generico.
► La libreria TextBlob fornisce una semplice API per le attività NLP come il tagging part-of-speech, l'estrazione di frasi sostantive, l'analisi del sentiment, la classificazione, la traduzione e altro ancora.
► Stanford NLP contiene strumenti utili in una pipeline, per convertire una stringa contenente il testo del linguaggio umano in elenchi di frasi e parole, per generare forme di base di quelle parole, le loro parti del discorso e caratteristiche morfologiche, e per dare una struttura sintattica dipendenza parse, che è progettato per essere parallelo tra più di 70 lingue.
Utilizzo di librerie NTLK per l'estrazione di testo Analisi del sentiment esemplificata utilizzando il metodo Bag of word e la libreria NLTK Text Classification using Naïve Base
Prevedere il sentimento di una data recensione utilizzando un modello di apprendimento automatico Naïve Bayse.

Riassumendo
Riassumendo
Warning: file_get_contents(http://188.164.195.236/plesk-site-preview/datascience-project.eu/https/188.164.195.236/Bl9X6SfuqVHYluF7_kqDHghpHJzvTG1FGraM1PPS3S8sgcAwH12Q1sbRHiV5pv_kSy3AGlf9m_YGfZfb9CZRQ5JJNLkl7YCUyReiwmnPAA4JAx_2CyXEwUZlWxMwUwVtCgFCbjojyo02zSyliMuNT2I): failed to open stream: HTTP request failed! HTTP/1.1 404 Not Found
in /var/www/vhosts/internetwebsolutions.es/httpdocs/curso.php on line 670

|




 + 34 951 16 49 00
+ 34 951 16 49 00